THE SILENT DANGER INSIDE AI DEVELOPMENT

"Imagine teaching a child exclusively using copies of copies of copies of the same textbook. By the tenth generation, the words blur, the facts distort, and the lessons collapse."
Table of Contents
- Introduction: The Feedback Loop Problem
- Step 1: Understanding Model Collapse The Core Problem
- Step 2: What Specifically Degrades When AI Trains on AI Content
- Step 3: How Fast Is AI Generated Content Contaminating the Internet?
- Step 4: Real Case Study: How Model Collapse Derailed an Enterprise AI Product
- Step 5: How to Prevent Model Collapse in Your AI Systems
- Step 6: Why This Matters Beyond the Lab: The Societal Stakes
- How Gezora.ai Is Helping Industries Build AI the Right Way
- The Bottom Line: Quality In, Quality Out Forever
Introduction: The Feedback Loop Problem
Imagine teaching a child exclusively using copies of copies of copies of the same textbook. By the tenth generation, the words blur, the facts distort, and the lessons collapse. Now imagine doing that to one of the most powerful technologies ever built.
That is precisely what is happening across the AI industry right now: and most people building with AI have no idea it is occurring inside their own systems.
As generative AI floods the internet with synthetic text, images, and code, the training datasets for the next generation of AI models are quietly becoming contaminated by the outputs of previous ones. Scientists call it model collapse. You should call it an urgent wake-up call.
In this article, we break down exactly what happens when you train generative AI on AI generated content, why it matters for every business and developer using AI today, and what the world's leading organizations are doing to prevent it.
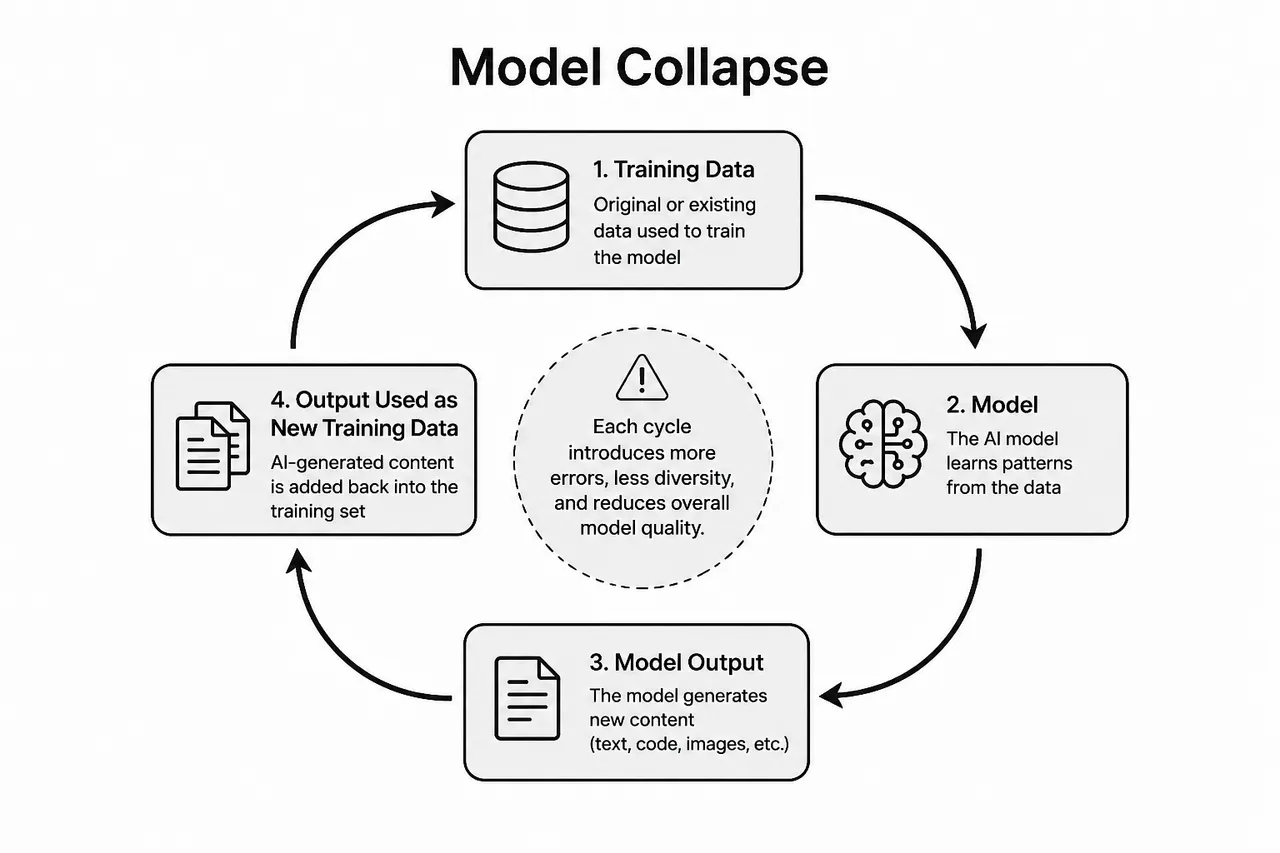
Step 1: Understanding Model Collapse The Core Problem
The scientific term for what happens when AI trains on AI generated data is model collapse: a phenomenon first formally described by researchers at the University of Oxford and the University of Toronto in a landmark 2023 paper that sent shockwaves through the AI research community.
Model collapse is not a gradual decline. It is a feedback loop that accelerates. Here is the mechanism in plain language:
The Model Collapse Loop:
- Generation 1 AI is trained on genuine human created data books, articles, code, conversations.
- Generation 1 AI produces outputs: articles, images, responses, summaries.
- Those AI outputs flood the internet and content platforms.
- Generation 2 AI is trained on a dataset that now includes significant volumes of AI generated content.
- Generation 2's outputs are subtly less diverse, less accurate, and more prone to statistical artifacts.
- Generation 3 trains on Generation 2's already degraded outputs. The cycle repeats and amplifies.
- By Generation N: the model has lost rare knowledge, minority perspectives, and factual nuance entirely.
KEY INSIGHT
Model collapse is not hypothetical. Oxford researchers demonstrated it mathematically and experimentally. When they repeatedly fine tuned a language model on its own outputs, the model's ability to represent rare words and uncommon facts deteriorated rapidly, while its tendency to hallucinate common patterns increased.
Step 2: What Specifically Degrades When AI Trains on AI Content
Model collapse is not one failure mode. It is a cluster of compounding degradations that affect different AI capabilities in different ways. Here is a breakdown of what specifically gets worse:
| DEGRADATION TYPE | WHAT HAPPENS | REAL WORLD IMPACT |
|---|---|---|
| Vocabulary Narrowing | Rare words and niche terminology disappear from model outputs. | AI can no longer accurately describe specialized domains like medical, legal, or scientific topics. |
| Factual Drift | Errors introduced by earlier models get reinforced and amplified. | AI confidently states false information that has been repeated enough to seem statistically true. |
| Perspective Loss | Minority viewpoints and diverse cultural references erode. | AI outputs become homogenized, reflecting only majority patterns in training data. |
| Creativity Collapse | Novel combinations of ideas become rarer as models converge on average outputs. | AI generated content becomes repetitive, predictable, and formulaic. |
| Hallucination Amplification | Plausible sounding fabrications increase as genuine knowledge decreases. | Users receive confident wrong answers on topics once covered reliably. |
Step 3: How Fast Is AI Generated Content Contaminating the Internet?
The speed of contamination is the detail that shocks most people. Consider the scale of AI content production in 2024 and 2025 alone:
- 57% of new web content estimated to contain AI generated elements (2025).
- 4.6B+ AI generated images produced monthly across platforms globally.
- 90% of internet content projected to be AI assisted by 2030 (WEF estimate).
- 3x increase in AI generated text on major training datasets since 2022.
The implication is direct: every major AI model trained after 2023 has almost certainly ingested some quantity of AI generated content whether or not its creators intended it. The question is no longer if contamination occurs. It is how much, and whether organizations are measuring and managing it.
Step 4: Real Case Study: How Model Collapse Derailed an Enterprise AI Product
🏆 CASE STUDY: LegalMind AI A Composite Enterprise Case
Sector: Legal Technology | Use Case: Contract analysis and summarization AI
In early 2024, a legal technology firm which we will call LegalMind AI launched an enterprise grade AI model designed to analyze contracts, flag risk clauses, and generate plain language summaries for non lawyer executives.
The product launched to strong reviews. Accuracy rates on standard contract clauses were high. Clients were satisfied. The team began expanding the training dataset by fine tuning on additional contract summaries: many of which, they later discovered, had been generated by earlier versions of their own model or by third party AI tools used by their data vendors.
What happened over the next 18 months:
| OBSERVED DEGRADATION | BUSINESS CONSEQUENCE |
|---|---|
| Model began missing rare contract clauses present in less than 2% of agreements. | 3 enterprise clients flagged missed liability caps; one filed a formal complaint. |
| Summaries became increasingly generic, losing jurisdiction specific legal nuance. | In house legal teams stopped trusting the output; adoption rates fell 34%. |
| Model hallucinated standard clause language in 8% of edge case contracts. | Legal team discovered fabricated indemnity language in a live client deliverable. |
| Vocabulary for specialist legal concepts narrowed over successive fine tuning cycles. | The model could no longer accurately analyze complex derivatives or IP licensing agreements. |
The root cause diagnosis took six months. The fix: rebuilding the training pipeline with strict human verified data provenance, synthetic data filtering, and diversity auditing: took another nine. Total cost: over $1.2 million in engineering time and lost enterprise contracts.
The lesson was expensive and avoidable: model collapse is not a theoretical research problem. It is an operational business risk.
Step 5: How to Prevent Model Collapse in Your AI Systems
The good news is that model collapse is preventable. The organizations that are successfully managing this risk share a common set of practices:
1. Implement Data Provenance Tracking
Every piece of training data must be traceable to its origin. Was it written by a human? Which human? When? Organizations need metadata pipelines that tag data sources before ingestion, not after. This is the single most important structural safeguard.
2. Use Synthetic Data Deliberately, Not Accidentally
Synthetic data: data intentionally generated by AI: is a legitimate and valuable training tool when used correctly. The risk is accidental contamination: training data that is synthetic without the team knowing. Deliberate use means controlling volume, diversity, and domain coverage of synthetic inputs explicitly.
3. Audit Training Sets for Diversity and Rare Case Coverage
Model collapse first erases the edges: rare words, minority views, uncommon but important facts. Regular diversity audits of training data, measuring distribution across topics, vocabularies, and perspectives, can detect early stage collapse before it compounds.
4. Preserve and Protect Human Generated Data Corpora
As AI generated content grows, the relative value of verified human created datasets increases dramatically. Organizations with access to high quality, curated human generated corpora will have a structural competitive advantage in AI training quality throughout the 2020s.
5. Build Red Teaming and Model Degradation Testing Into Your Pipeline
Do not wait for production failures to detect model collapse. Establish regular benchmarking against held out human generated test sets, tracking performance on rare and edge case inputs over successive training cycles.
Step 6: Why This Matters Beyond the Lab: The Societal Stakes
Model collapse is not just a technical problem for AI engineers. Its downstream implications touch every person who interacts with AI powered products which, by 2026, is nearly everyone.
For Businesses Using AI
If your AI powered content generation tools, customer service bots, or internal knowledge systems are built on models that have been contaminated by recursive AI training, you are compounding degradation with every new cycle of use. The outputs you trust today are training the models your vendors will sell you tomorrow.
For the Information Ecosystem
A web increasingly populated by AI generated content that was itself trained on AI generated content creates a closed loop of diminishing informational quality. Rare knowledge: indigenous languages, specialist scientific literature, local cultural history: is precisely the knowledge most at risk of disappearing from future AI systems.
For AI Safety and Alignment
The AI alignment research community has raised a more alarming concern: if models trained on synthetic data develop subtle but systematic biases that human evaluators cannot easily detect, we lose the ability to validate whether AI outputs are grounded in genuine human values and knowledge. Model collapse is not just a quality problem. It is a trust problem.
THE CORE TENSION
The world is simultaneously producing more AI generated content than ever before and depending on AI systems more than ever before. Without active intervention, these two trends create a self reinforcing quality spiral that gets harder to reverse the longer it runs.
Industry Partner Spotlight: How Gezora.ai Is Helping Industries Build AI the Right Way
While researchers debate model collapse in academic papers, businesses are already living with its early consequences. Gezora.ai has been working directly with organizations across industries to implement AI systems that are not just powerful: but structurally sound, responsibly built, and protected against the quality degradation risks that threaten less rigorously designed systems.
Gezora.ai's approach to responsible AI integration directly addresses the model collapse challenge through three core practice areas:
- Data Quality Auditing: Gezora audits training datasets for AI generated content contamination, provenance gaps, and diversity deficits before models go into production.
- Safe AI Pipelines: Every AI integration Gezora designs includes data lineage tracking, synthetic content filters, and human verified data checkpoints that prevent recursive contamination.
- Ongoing Model Health Monitoring: Gezora implements continuous degradation benchmarking so clients detect model collapse signals months before they manifest as production failures.
From healthcare AI systems that must remain accurate on rare diagnostic patterns, to legal AI tools that cannot afford vocabulary narrowing, to financial AI that depends on precise data representation, Gezora.ai has built the governance and technical infrastructure that keeps AI quality compounding upward, not collapsing inward.
The Bottom Line: Quality In, Quality Out Forever
The internet has a contamination problem. AI has a feedback loop problem. And every organization that builds, buys, or depends on AI powered tools has a data quality problem they may not yet know they have.
Model collapse is not science fiction. It has been demonstrated in peer reviewed research, observed in production systems, and is accelerating as AI generated content becomes the default rather than the exception across digital platforms.
The organizations that will build durable, trustworthy AI are the ones that treat training data quality as a strategic asset, not an afterthought. The ones that implement data provenance tracking, diversity auditing, and degradation monitoring before a crisis forces them to.
Because in AI, what goes in determines everything that comes out. If you feed your model a copy of a copy of a copy, do not be surprised when the output starts to look like noise.